Looking through the list of TEI projects, I noticed eZISS: Scholarly Digital Editions of Slovenian Literature. This project is hosted by the Scientific Research Centre of the Slovenian Academy of Sciences and Arts in Ljubljana, Slovenia. I was interested in eZISS because the material was unfamiliar and the project is extensively documented. Although the texts are only in Slovenian, the entire website is available in English.
eZISS offers “selected Slovenian texts with integrated facsimiles, transcription and scholarly commentary, in some cases including audiovisual recordings” (eZISS). The project is described as existing at the intersection of Slovenian literature, ecdotics (philological study of texts and their presentations), and modern information technology (eZISS).
There is a large focus on encoding, which is likely because information technology is part of this intersection. Encoding isn’t just a vehicle for showcasing texts but a fundamental aspect of the project. On the main page of the site, they write:
The complex digital encoding of texts with facsimiles, transcriptions, critical apparatus and audiovisual recordings is achived with the help of open standards of textual markup: Unicode, XML, and the TEI Guidelines. This foundation helps the editions to be better resistant to technological change, software independent and compatible with other standardised digital resources. From the source XML, an HTML version is created with XSLT stylesheets; to read the HTML, only a standard browser is required (eZISS).
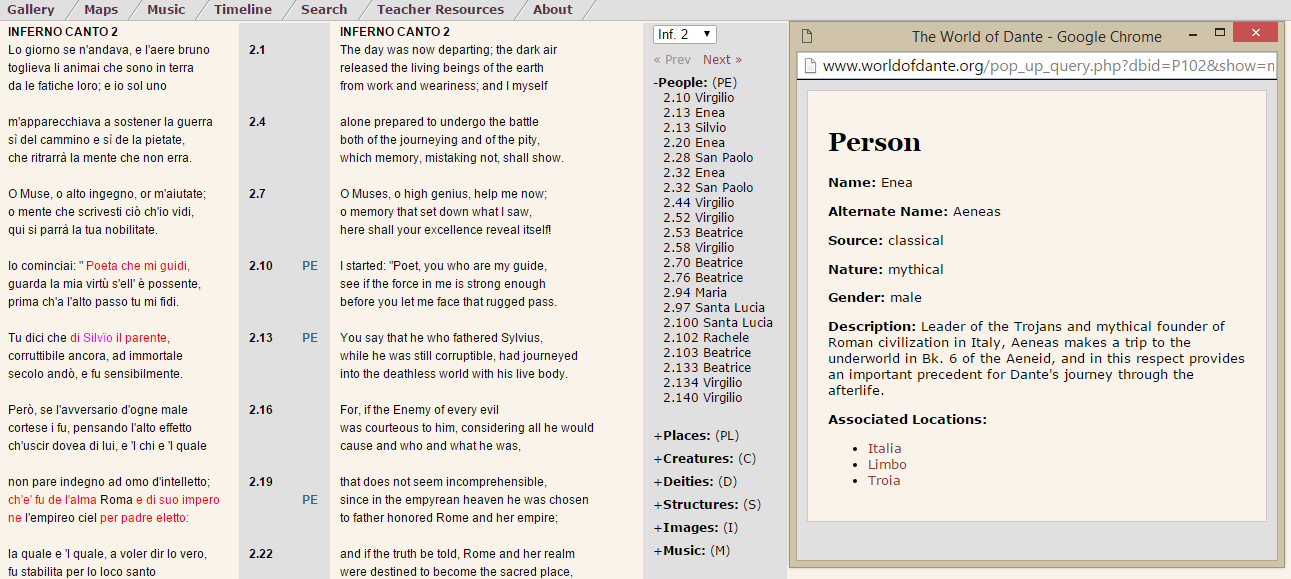
The researchers are also very open with their sources and code. The texts are all licensed under a Creative Commons Attribution-Share Alike license. As an example, I looked at the Freising Manuscripts, the first document of Slovenian culture.
 From here, you can view all of the components online or save them to your computer. Interestingly, the website states that you will “also get the XML/TEI files, suitable for further processing” (Freising Manuscripts).
From here, you can view all of the components online or save them to your computer. Interestingly, the website states that you will “also get the XML/TEI files, suitable for further processing” (Freising Manuscripts).
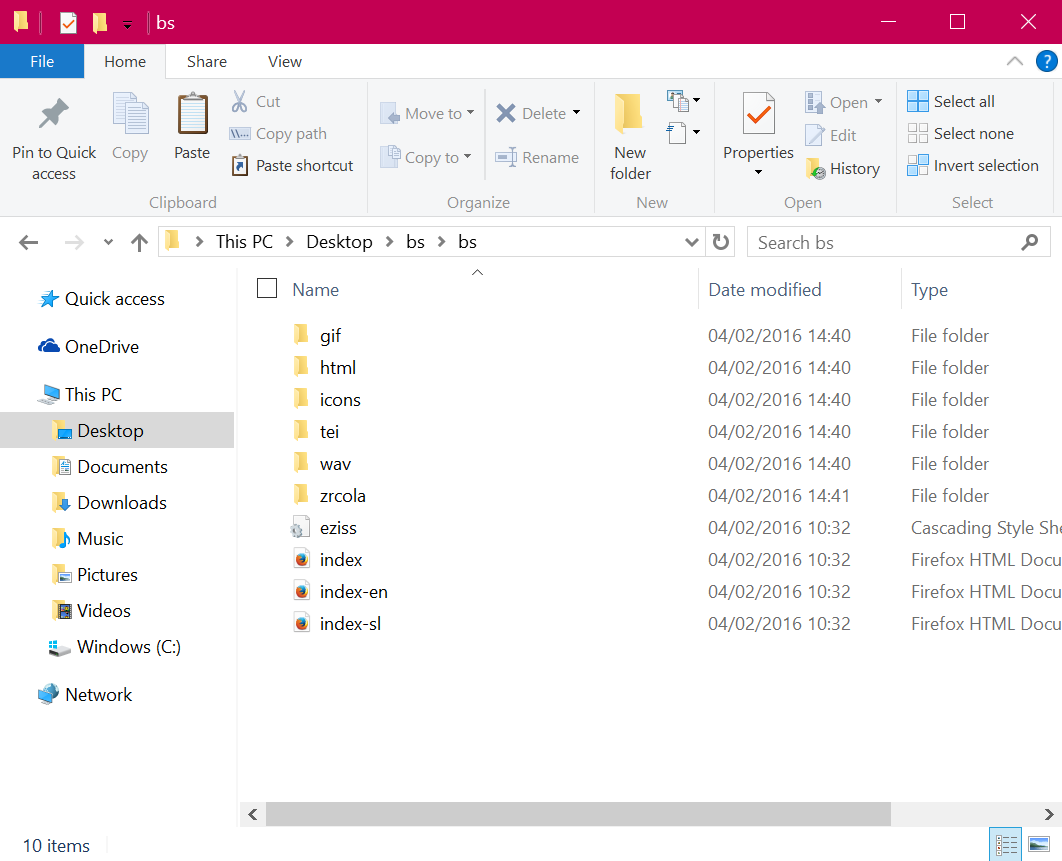
The downloaded edition provides everything from the icons used on the webpage to the facsimiles (gif folder) to the TEI files.
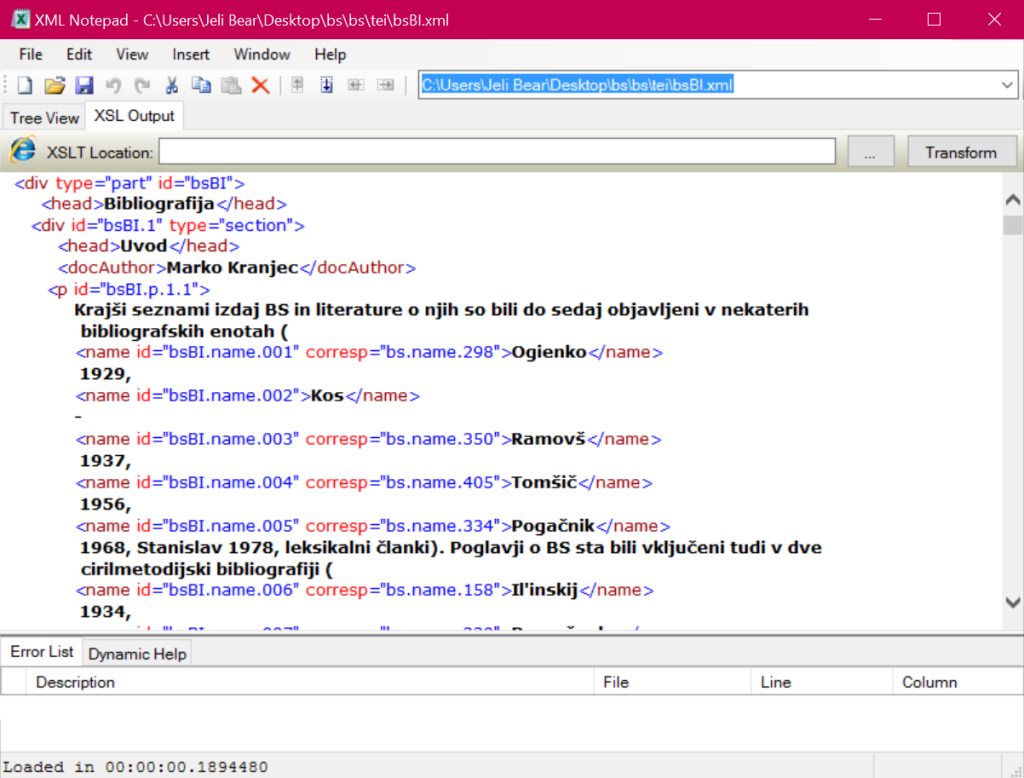
What impressed me most about this project is the emphasis on openness, either through the CC license or through explicit mentions of further processing.
Lastly, the project is very well documented. There are three English publications on the development of the eZISS editions (and several more in Slovenian). According to the article, “E-Slomšek: A TEI Encoding of a Critical Edition of 19th Century Slovenian Rhetoric Prose” by Erjavec, Ogrin, and Faganel, in small nations such as Slovenia, “publishing critical editions with facsimile, transcriptions and apparatus in traditional print form faces great economic barriers, primarily due to the very small book market” (Erjavec et al., 2004, p. 31). Digital editions of this work, thus, have a “much better chance… of preserving, interpreting and making available Slovenian cultural heritage” (p. 31). In this case, the availability of open standards allowed for projects that the researchers saw as contributing to national identity and preservation of culture.
References
Erjavec, T., et al. (2004) E-slomšek: A TEI encoding of a critical edition of 19th century Slovenian rhetoric prose. Pregled NCD 5: 31-41.
eZISS (2011). About. eZISS: Scholarly digital editions of Slovenian literature. Assessed February 2, 2015
TEI (2007). Scholarly digital editions of Slovenian literature. Accessed February 2, 2015